Menu
Vestrex
Automation & orchestration for strategic decision making
MDS
Maptek Data System
MCF
Maptek Compute Framework
MOE
Maptek Orchestration Environment
Join our early access program to unlock value for your organisation.
BlastLogic
Drill & blast management
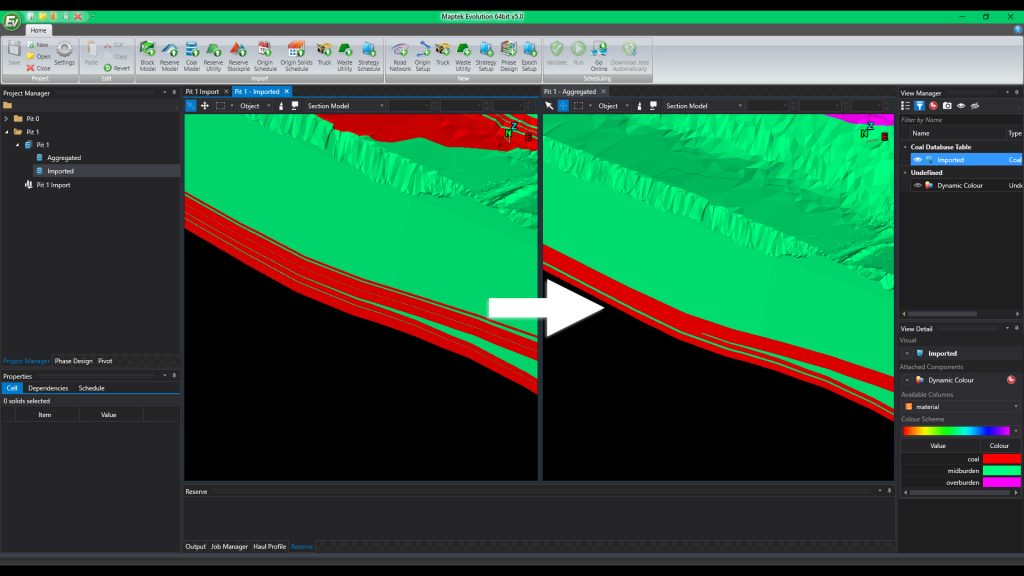
Evolution
Scheduling and haulage scenarios
VisionV2X
Reliable proximity awareness underground
GeoSpatial Manager
Dynamic survey surface updates
Vulcan
Mine planning & geological modelling
GeologyCore
Connected geological modelling solution
DomainMCF
Machine learning assisted domain modelling
Maptek Resource Tracking
Material tracking & reconciliation systems
Laser Scanners
Laser scanning & imaging
PointStudio
Point cloud processing & analysis
Sentry
LiDAR-based stability & convergence monitoring
PointModeller
Derive value from airborne or mobile sensor data
Products
Vulcan
Laser
Scanners
PointStudio
BlastLogic
Evolution
Sentry
GeologyCore
GeoSpatial Manager
VisionV2X
DomainMCF
PointModeller
Resource Tracking