The Grand Challenge for Data and Technology in Mining
 Turning data and the technologies around data into something useful is what I call the Grand Challenge.
Turning data and the technologies around data into something useful is what I call the Grand Challenge.
This challenge has been ever present in Maptek’s thinking.
Three waves of technology have washed over us in the last few years which are reshaping this thinking.
The first one is Big Data, the second is the Internet of Things (IoT) and the third is Artificial Intelligence (AI) & Machine Learning.
As with most emerging tech hypes, the full benefits for our industry are yet to be seen. However, these waves are playing a large part in the Maptek Technology Roadmap as we look to take these concepts and turn them into value for the industry.
In this three-part blog I will explore these emerging technologies and then discuss how they fit into our roadmap, with the end goal of optimisation of entire mining operations.
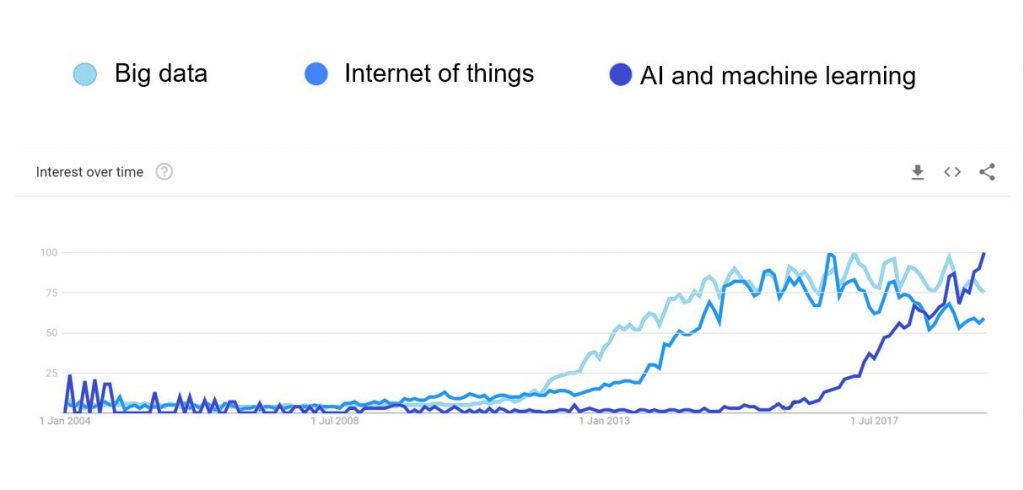
Google Trends shows the growing interest in Big Data, the Internet of Things, and AI & Machine Learning.
Big Data
The mining industry and Maptek have been working with Big Data for years. First with high-resolution grid models for coal geology, now with block and HARP models of many diverse resource types and more recently with storage and visualisation of point cloud data collected by our laser scanning instruments.
We have our own formats for this kind of data because it is too big to store on conventional servers, particularly if you want to interact with it in 3D.
So what’s the big deal? What has changed?
There’s more to Big Data now than just the volume of data. The variety of data today is enormous. Remote sensing data, assay data, measure while drilling data, fleet management time series data, time performance data and point cloud data from laser scanners and drones. There’s a new technology coming into the industry, distributed acoustic sensing, that’s like having a microphone every half a metre down a piece of optical fibre, which can be used for all sorts of things.
The velocity at which this data is coming at us is only increasing. And the time we have to act on it seems to be getting shorter and shorter.
The Internet of Things
The IoT is responsible for much of this data. You can think of it as a confluence of several things: sensors that are costing less and less, putting data out over the ever-improving digital networks, along with the wide adoption of established protocols for sensors talking to computers, computers talking to sensors and computers talking to other computers.
Maptek Drive, our mobile mapping solution, and Maptek Sentry slope stability monitoring are examples of systems which can generate gigabyte payloads of data in a very short time.
Having low cost sensors on every piece of equipment has also led to a less obvious problem – one of veracity. Veracity is how accurate the data is – how well correlated it is to the real phenomenon of interest. Data of high veracity has low noise. The Internet of Things generally causes data veracity to go down. For example, measure while drilling data – an automated sensor feed from a drilling rig – versus manually sampling the hole after drilling with a downhole geophysical probe: velocity is up, veracity is down. Laser scanners versus survey pickups: volume is up, velocity is up but any single point is not as accurate.

Simon speaks about the Grand Challenge at a Maptek Technology Forum earlier this year.
These factors make getting data from devices to software difficult, let alone doing anything useful with it. In short, the IoT has created a Big Data management problem.
Volume, variety and velocity of data being collected is up, but veracity is down and many mining operations today feel there’s simply too much data floating around that is not instantly useful. Because it’s not instantly useful, no-one has enough time to regularly and sustainably extract the value out of it to make effective use of it.
So much value is latent in the data that’s been collected but not used.
The five Vs of Big Data
Volume – more data than ever is being collected
Variety – there’s a greater range of data sources
Velocity – data is being collected faster than ever
Veracity – more data can often equal less accuracy
Value – it’s a challenge to unlock the latent value
AI & Machine Learning
Finally we get to AI & Machine Learning … is it the answer to managing all this data?
While it may not be the total answer, it’s certainly got a lot to offer.
Its spectacular recent rise is due to ongoing advances in available computing power improving Big Data management and some key breakthroughs in algorithms – the ways we program computers.
For the first time we’ve got cost and time effective ways of coding computers to do things by example rather than by recipe. We used to only be able to tell a computer what to do by a recipe of steps. Instead of making algorithms better by coming up with more or better recipes we can now show the same algorithm more examples: more samples from – or more representations of – the underlying model we’re trying to recreate.
In other words we train the computer with more data, and thanks to Big Data and IoT technologies more data is exactly what we happen to have.
Bringing it all together
You can see how complementary these three waves are: Big Data techniques give us ways of gathering and managing data from all of those feeds, IoT technologies are bringing more and more data of interest in from the physical world at a lower cost, albeit with some veracity and hence value issues, and AI & Machine Learning is a way of getting to that value, and loosely speaking, the more data it sees the better it can get.
So now we arrive at the Grand Challenge of today.
Based on the potential of these three waves, how do we deliver better decision making outcomes with these technologies in ways that are practical, robust and sustainable? Not just in a prototype or proof of concept but in industrial strength ways that stand up to the rigours and turmoil of the daily grind.
Find out how Maptek is positioning itself to tackle the Grand Challenge next month in Part II of this blog.

